
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 파이썬
- 파이썬 셀레니움
- #비정형 데이터 #네이버 #지도 #크롤링
- 위도경도
- #위도#경도#비정형데이터#크롤링
- 숫자빼고 중복되는 코드동작법
- 코딩
- 구글 지오코드
- 웹크롤링
- #크롤링 #웹문서
- 셀레니움
- #비정형#카카오api#api#크롤링
- 웹매크로 #세잔느
- #K-means #Clustering
- 카카오APi
- Today
- Total
지방이의 Data Science Lab
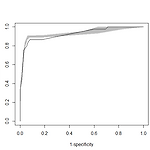 [R] plot: 두 라인 사이 색칠 법
[R] plot: 두 라인 사이 색칠 법
ROC 커브를 그리기 위해서 찾아보다 알게됐다. 5fold인경우 그림에 다 담아내면 지저분해져서 ==>max값 min값의 차이 부분을 쉐이딩 해주고 median값을 선으로 나타냈다. 라인 사이 색칠법은 간단하다. polygon이라는 명령어를 사용해주면된다. 1 polygon(c(fpr1,rev(fpr2)),c(tpr1,rev(tpr2)),col="grey", border = 'grey')
cv_id['train'][0] ==> '1,10,100' cv_id['train'][0].split(",") ==>'1', '10', '100' train0 = [int(i) for i in cv_id['train'][0].split(",")] ==>[1, 10,100]
imbalance일때 학습시키려면 계층유지셔커서 쪼개는 방법 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 X = flatten.drop('KIS_credit_&_2018',axis=1) y = flatten['KIS_credit_&_2018'] #방법1 from sklearn.model_selection import train_test_split train_test_split(X, y, random_state=0, stratify=y, shuffle=True) train=flatten.iloc[train_inds] test=flatten.iloc[test_inds] #방법2 from sklearn.model_selecti..
1 2 3 4 5 6 7 8 9 10 11 #1. 0으로 잘못 표기되어 나왔을 경우 mean값으로 대체 pledge = pd.read_csv('train_pledge.csv', engine='python') non_combat = np.array(pledge['non_combat_play_time']) non_combat_mean = non_combat[np.nonzero(non_combat)].mean() pledge['non_combat_play_time'] = np.where(pledge['combat_play_time']>0, pledge['non_combat_play_time'] + non_combat_mean, pledge['non_combat_play_time']) #2. na라는 모든 값을..
바꾸고싶은 x변수들만 선택 후, 변경 1 2 3 4 5 6 7 8 9 10 11 # 1번째 방법 yearmonth_norm = (yearmonth_num-yearmonth_num.mean())/np.std(yearmonth_num) # 2번째 방법 (추천) x_names = data.columns.to_list() del x_names[0:5] from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler(copy=True, feature_range=(0, 1)) data[x_names] = pd.DataFrame(scaler.fit_transform(data[x_names].values))