
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 웹크롤링
- 셀레니움
- 코딩
- #비정형 데이터 #네이버 #지도 #크롤링
- 파이썬
- 파이썬 셀레니움
- 숫자빼고 중복되는 코드동작법
- 구글 지오코드
- #위도#경도#비정형데이터#크롤링
- 카카오APi
- #비정형#카카오api#api#크롤링
- #크롤링 #웹문서
- 웹매크로 #세잔느
- #K-means #Clustering
- 위도경도
- Today
- Total
지방이의 Data Science Lab
 [SQL] NTILE( )
[SQL] NTILE( )
1 2 3 SELECT first_name, email, salary, department, NTILE(5) OVER(PARTITION BY department ORDER BY salary DESC) FROM employees
 [python] 리스트 특성
[python] 리스트 특성
1. list와 [ ]의 차이점 (1) list에는 int를 담을 수 없으나 [ ]에는 가능함 1 2 3 4 5 6 myinput = int(33) print(list(myinput)) # TypeError print([myinput]) # [33] (2) string 상태를 list에 담으면 33 -> 3, 3인상태로 담겨지고, [ ]에 담으면 그대로 담김 1 2 3 4 5 6 myinput = int(33) print(list(str(myinput))) # ['3', '3'] print([str(myinput)]) # ['33'] 2. list와 [ ]의 공통점 1 2 3 4 5 6 7 8 9 10 11 12 mylist = ['33'] print(''.join(mylist)) # 33 mylist ..
 [Python] Datetime Review
[Python] Datetime Review
#1. Datetime Review 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from datetime import datetime my_year = 2017 my_month = 1 my_day = 2 my_hour = 13 my_minute = 30 my_second = 15 # 2017년 1월 2일 my_date = datetime(my_year,my_month,my_day) # [1] datetime.datetime(2017, 1, 2, 0, 0) # 2017년 1월 2일 13:30:15 my_date_time = datetime(my_year,my_month,my_day,my_hour,my_minute,my_second) # [1] datetime.datetime(..
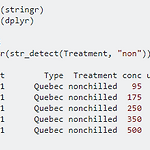 [R] 데이터 string 부분 매칭되는 row 불러오기
[R] 데이터 string 부분 매칭되는 row 불러오기
1 2 3 4 library(stringr) library(dplyr) CO2 %>% filter(str_detect(Treatment, "non") 코드 해석: CO2데이터의 Treatment 열에 'non'이라는 글자를 포함하면 그 row들을 불러와라.
 [python] 리스트를 카운트해서 dictionary를 만들어보기
[python] 리스트를 카운트해서 dictionary를 만들어보기
방법은 두가지가 있다. (1) try/except를 통해서 직접 만들기 (2) count 기능 사용해서 카운트 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #첫번째 방법 A = [1, 9, 6, 3, 3, 1, 7, 6, 9] dict_ = {} for i in A: try: dict_[i] += 1 except: dict_[i] = 1 dict_ #두번째 방법 A = [1, 9, 6, 3, 3, 1, 7, 6, 9] d = {x:A.count(x) for x in A} d