
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 카카오APi
- #위도#경도#비정형데이터#크롤링
- 위도경도
- 코딩
- 웹크롤링
- 숫자빼고 중복되는 코드동작법
- 파이썬 셀레니움
- #K-means #Clustering
- 구글 지오코드
- 셀레니움
- #크롤링 #웹문서
- 파이썬
- #비정형 데이터 #네이버 #지도 #크롤링
- 웹매크로 #세잔느
- #비정형#카카오api#api#크롤링
- Today
- Total
목록All (143)
지방이의 Data Science Lab
 [Python] Datetime Review
[Python] Datetime Review
#1. Datetime Review 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from datetime import datetime my_year = 2017 my_month = 1 my_day = 2 my_hour = 13 my_minute = 30 my_second = 15 # 2017년 1월 2일 my_date = datetime(my_year,my_month,my_day) # [1] datetime.datetime(2017, 1, 2, 0, 0) # 2017년 1월 2일 13:30:15 my_date_time = datetime(my_year,my_month,my_day,my_hour,my_minute,my_second) # [1] datetime.datetime(..
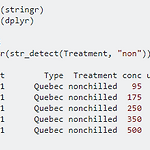 [R] 데이터 string 부분 매칭되는 row 불러오기
[R] 데이터 string 부분 매칭되는 row 불러오기
1 2 3 4 library(stringr) library(dplyr) CO2 %>% filter(str_detect(Treatment, "non") 코드 해석: CO2데이터의 Treatment 열에 'non'이라는 글자를 포함하면 그 row들을 불러와라.
 [python] 리스트를 카운트해서 dictionary를 만들어보기
[python] 리스트를 카운트해서 dictionary를 만들어보기
방법은 두가지가 있다. (1) try/except를 통해서 직접 만들기 (2) count 기능 사용해서 카운트 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #첫번째 방법 A = [1, 9, 6, 3, 3, 1, 7, 6, 9] dict_ = {} for i in A: try: dict_[i] += 1 except: dict_[i] = 1 dict_ #두번째 방법 A = [1, 9, 6, 3, 3, 1, 7, 6, 9] d = {x:A.count(x) for x in A} d
 [Python] 두 리스트에서 다른 것 찾기
[Python] 두 리스트에서 다른 것 찾기
temp1 = ['One', 'Two', 'Three', 'Four'] temp2 = ['One', 'Two'] 가 있을 때, temp3 = ['Three', 'Four']를 얻어내자. 1 2 s = set(temp2) temp3 = [x for x in temp1 if x not in s]
 [R] 데이터 시각화를 위한 데이터 전처리
[R] 데이터 시각화를 위한 데이터 전처리
시작 예를 들어, manufacturer에 보이는 저 audi. audi의 displ (engine displacement in liters)값을 몽땅 합쳐서 보고 싶다! 라고 판단 되면 아래 코드처럼 쓸 수 있습니다. 1 2 library(car);data = mpg aggregate(displ~manufacturer,data,sum) 다시말해, data에서 manufactuerer별로 총 displ합이 어떻게 돼? 하고 명령하는 것입니다. 아~ aggregate은 데이터를 가공할 수 있는 것이며, aggregate(y~x, data, function) 형태로 되어 있고, x별로 y값을 sum, mean, 등등 을 해달라고 부탁 할 수 있구나..! 라고 느끼실 것입니다. 아주 좋은 기능입니다. 여기서 ..
 [R] 보고서 작성에 쓰이는 데이터 시각화 색상 고르는 팁
[R] 보고서 작성에 쓰이는 데이터 시각화 색상 고르는 팁
* 소소한 보고서 TIP 보고서에 담겼을 때 예쁜 색상 팁: geom_bar부분에 보이는 aplha(색상 투명도)값을 조정할 것 파스텔 톤이 아니어서 쨍한, 즉, Solid한 색상(alpha=1) 을 사용하면 촌스러워 진다. alpha값은 투명도를 조정하는 것인데, 1에 가까울 수록 solid한 색이고, 0에 가까울 수록 pastel색이다. alpha을 조정하여 파스텔 톤으로 변경하면 좀 더 고급지게 보고서에 담을 수 있다. 내 기준 0.6정도로 바꿔 투명하게 만들었을 때가 가장 예쁘게 담기는 색이라 생각한다. 그래야 보고서 상 강조하고 싶은 내용에 빨간색으로 표시를 하며 원하는 내용에 더 집중할 수 있다. 아래 그림을 비교해 보면 왜 alpha를 조정해야하는 지 느낄 수 있을 것이다. (library(..
 [R] 데이터 시각화: Bar Plot
[R] 데이터 시각화: Bar Plot
1 2 3 4 5 6 7 8 9 10 11 12 13 libraray(dplyr); library(ggplot2);library(forcats) df = data%>%filter(categorical1=="aa") temp = aggregate(df$numerical, by = list(df$categorical2), FUN = sum) colnames(temp) = c('categorical2', 'numerical') temp%>% mutate(name = fct_reorder(categorical2, numerical)) %>% ggplot( aes(x=categorical2, y=numerical)) + labs(x="") + geom_bar(stat="identity", fill="#68C8CB..