
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- #K-means #Clustering
- 코딩
- 웹크롤링
- 파이썬 셀레니움
- 파이썬
- 웹매크로 #세잔느
- 셀레니움
- #비정형 데이터 #네이버 #지도 #크롤링
- #비정형#카카오api#api#크롤링
- 위도경도
- #위도#경도#비정형데이터#크롤링
- 숫자빼고 중복되는 코드동작법
- 구글 지오코드
- #크롤링 #웹문서
- 카카오APi
Archives
- Today
- Total
지방이의 Data Science Lab
[python] file 속 데이터들을 전부 가져오는 방법 glob.glob 본문
|
1
2
|
import glob
(glob.glob("../data/x/*/*.csv"))
|
위 코드 번역
==>data라는 폴더안에 들어있는 모든 폴더에 들어가서 .csv에 해당하는 모든 파일을 데려와서 directory를 보여라.

더보기
응용: ravel과 glob를 이용해 데이터 전처리 하는 방법 (옆으로 늘어져있던걸 밑으로 늘리는 방법)
https://jlim0316.tistory.com/122
ravel c에 이어지는
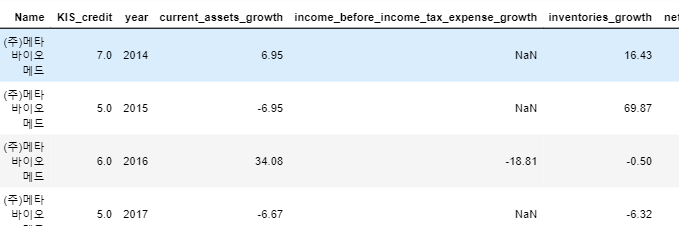
'Data Analysis > Python' 카테고리의 다른 글
| [python] x, y 쪼개기, train, test 쪼개기 (1) | 2020.02.09 |
|---|---|
| [python] imputation (0) | 2020.02.08 |
| [python] one row to multiple rows (0) | 2020.02.07 |
| [python] 원하는 string포함한 pd.dataframe 필터링 (0) | 2020.02.05 |
| [python] key id가 multiple 관측치일때 갯수 일정하게 (1) | 2020.02.01 |
Comments